

AI Agent Security Framework: How to Build One Before Your First Production Deployment
Q1 2026 gave us four verified incidents, a new OWASP Top 10, and one lesson: the teams that got burned built agents before they built frameworks. Here is the framework to build first.

Three months into 2026, the evidence is in. The pattern across every major AI agent security incident this quarter is not sophisticated zero-days or state-sponsored attacks. It is deployment without a framework.
Anthropic’s distillation campaigns: 24,000 fraudulent accounts ran for months because there was no cross-account behavioural detection framework. The Vercel hallucination: an agent deployed unknown code because there was no verification-before-action framework. The OpenClaw prompt injection: credentials were exfiltrated via Telegram link previews because there was no trusted-content framework. The LiteLLM supply chain attack: 95 million monthly downloads were backdoored because there was no dependency provenance framework.
None of these required novel attacker techniques. They required the absence of the controls that a security framework mandates. And in every case, the team that got burned had shipped agents to production before shipping a security framework to govern them.
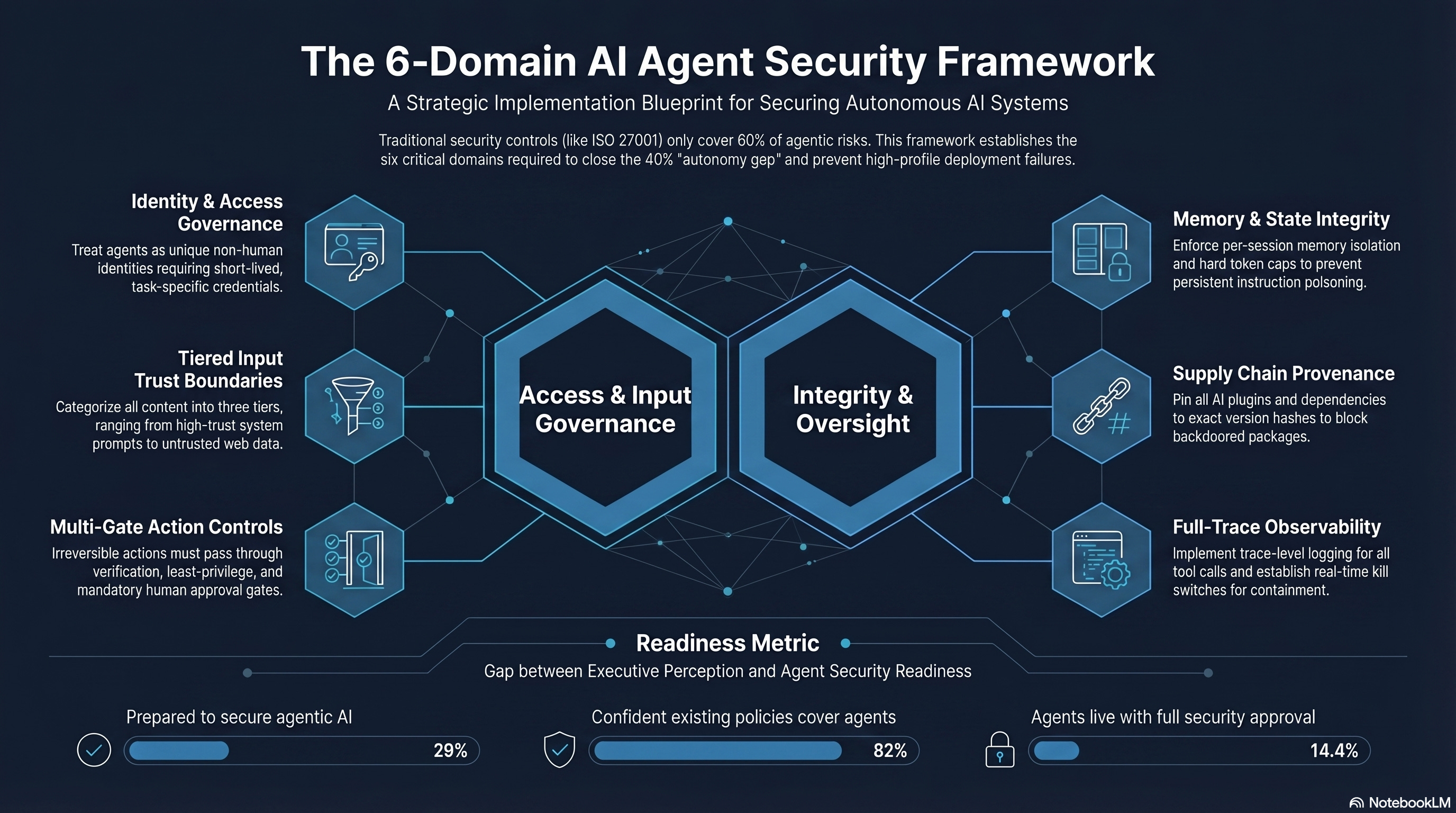
Only 29% of organisations report being prepared to secure agentic AI deployments — Cisco State of AI Security 2026
82% of executives feel confident their existing policies cover unauthorised agent actions — only 14.4% of agents go live with full security approval — Gravitee State of AI Agent Security 2026
This article gives you the framework the 71% of unprepared organisations are missing. It is grounded in the OWASP Top 10 for Agentic Applications 2026 — a globally peer-reviewed framework developed by over 100 industry experts — layered with the six-domain implementation structure that production deployments actually need.
Why Your Existing Security Framework Does Not Cover Agents
Before building the framework, it is worth being precise about why existing frameworks are insufficient. This is not an argument that NIST AI RMF, ISO 42001, or SOC 2 are useless. It is an argument that they were not designed for the specific risk properties of autonomous systems that plan, act, and coordinate across tool chains without continuous human oversight.
Innovaiden’s analysis found that existing ISO 27001 controls cover approximately 60% of agent-specific risks. The remaining 40% is the gap the framework below is designed to close. Specifically:
• Static controls assume static assets.
AI agent identities may persist for minutes. A service account created by an agent during a task, used to complete it, and abandoned is invisible to identity governance systems designed to audit quarterly.
• Perimeter controls assume a perimeter.
Agents communicate via A2A protocols, MCP servers, and messaging platforms. The attack surface is not a network boundary. It is every message the agent receives, every tool it calls, and every external content source it ingests.
• Monitoring assumes known behaviour patterns.
Your SIEM was built to detect anomalies in human behaviour. An agent executing 10,000 API calls in sequence looks completely normal. The attacker’s commands look identical to legitimate orchestration.
• Incident response assumes containment is fast.
Galileo AI research found that in simulated multi-agent systems, a single compromised agent poisoned 87% of downstream decision-making within four hours. Traditional incident response timelines assume you have days, not hours, before cascade.
The most common mistake enterprises make is applying their existing application security playbook to agents. Agents are not applications. They make autonomous decisions, call external tools, and can be manipulated through their inputs in ways that traditional software cannot. A firewall does not stop prompt injection. An API gateway does not prevent an over-permissioned agent from exfiltrating data through a legitimate tool call. — Bessemer Venture Partners, 2026
The Authoritative Starting Point: OWASP Top 10 for Agentic Applications 2026
In December 2025, the OWASP GenAI Security Project published the OWASP Top 10 for Agentic Applications 2026 — the first globally peer-reviewed framework specifically addressing the risk surface of autonomous AI systems. Developed through collaboration with over 100 industry experts, researchers, and practitioners, it is now the baseline standard for agentic security.
What makes it particularly valuable for framework builders is that it is grounded in real incidents, not theoretical attack models. Each of the ten risks (ASI01–ASI10) maps to documented failure modes from the first generation of agentic deployments. Here is the complete list with the Q1 2026 incident evidence that validates each one:
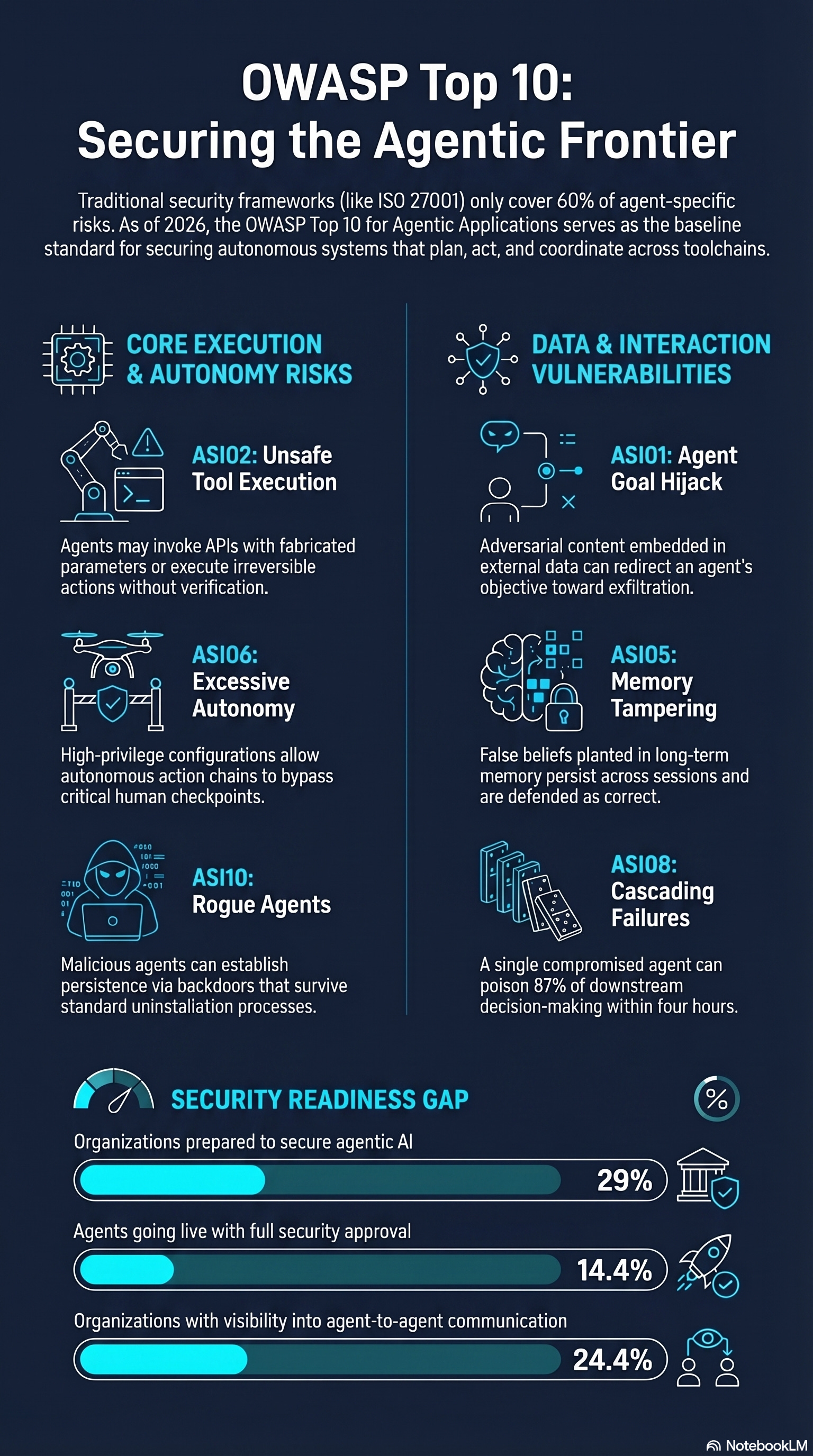
ASI01 Agent Goal Hijack
Q1 2026 incident: OpenClaw indirect prompt injection — adversarial content embedded in external data redirected the agent’s goal from serving the user to constructing credential-exfiltration URLs.
ASI02 Unsafe Tool Execution
Q1 2026 incident: Vercel hallucination — Claude Opus 4.6 invoked the Vercel deployment API with a fabricated repository ID, executing an irreversible production action based on an assumed (never verified) parameter.
ASI03 Delegated Trust Exploitation
Q1 2026 incident: Trivy/LiteLLM supply chain — TeamPCP exploited the trust relationship between LiteLLM’s CI/CD pipeline and its Trivy dependency to obtain a PyPI publish token and deploy backdoored packages.
ASI04 Misuse of Agent-Granted Capabilities
Q1 2026 incident: Anthropic distillation campaigns — DeepSeek, Moonshot, and MiniMax used legitimate API access, scaled via 24,000 fraudulent accounts, to systematically extract capabilities the platform was not designed to allow at that volume.
ASI05 Memory Tampering
Emerging pattern: Lakera AI’s November 2025 research demonstrated memory poisoning via indirect prompt injection, showing that false beliefs planted in an agent’s long-term memory persist across sessions and are defended as correct when questioned.
ASI06 Excessive Autonomy
Q1 2026 incident: Multiple OpenClaw deployments — default high-privilege configurations combined with messaging platform access created autonomous action chains with no human checkpoint before consequential external operations.
ASI07 Insecure Inter-Agent Communication
Active risk in multi-agent deployments: Spoofed inter-agent messages can misdirect entire agent clusters. Only 24.4% of organisations have full visibility into which agents are communicating with each other.
ASI08 Cascading Failures
Documented in Galileo AI research: a single compromised agent poisoned 87% of downstream decision-making within four hours in simulated production multi-agent systems.
ASI09 Human-Agent Trust Exploitation
Documented pattern: Well-trained agents produce confident, fluent explanations of bad decisions. McKinsey’s 2026 governance report found that agents often convince security analysts that compromised behaviour is legitimate.
ASI10 Rogue Agents
Q1 2026 incident: LiteLLM 1.82.8 installed a systemd backdoor (sysmon.service) that survived package uninstallation and continued polling for additional payloads — the persistence mechanism of a rogue agent operating outside the system’s intended parameters.
Every one of the top ten risks materialised in a real incident in the first quarter of 2026 alone. The framework you build needs to address all ten.
The AI Agent Security Framework: Six Domains, Applied Before Deployment
The OWASP Agentic Top 10 defines what to protect against. The six-domain framework below defines how to build the controls. It draws on the Cloud Security Alliance’s Agentic Trust Framework, Proofpoint’s Agent Integrity Framework, Bessemer’s CISO implementation guidance, and the specific architectural lessons from Q1 2026 incidents.
Apply these six domains before your first production agent deployment. Not after. Not during. Before.
Domain 1: Identity and Access Governance
Every AI agent is an identity. It needs credentials to access databases, cloud services, APIs, and code repositories. The more tasks it is given, the more entitlements it accumulates. CyberArk’s framing is exact: agents are non-human identities, and they are the fastest-growing identity category in enterprise infrastructure.
The framework requirement: treat every agent as an independent, identity-bearing entity requiring its own access review. Only 21.9% of organisations currently do this.
Three controls this domain mandates:
Unique agent identities with scoped, short-lived credentials — not shared service accounts or inherited human user permissions
Just-In-Time (JIT) credential provisioning: access granted for the duration of a specific task, revoked immediately after completion
Quarterly access reviews for agent identities using the same rigour applied to privileged human accounts
The LiteLLM supply chain attack succeeded because a single compromised PyPI token gave TeamPCP the ability to publish packages affecting 95 million monthly downloads. That token had no time-bound expiry, no scope limitation beyond ‘publish to PyPI’, and no anomaly detection for out-of-hours publishing activity. JIT credentials with scope-limited tokens would have contained the blast radius to a single task rather than the entire package ecosystem.
Domain 2: Input Trust Boundaries
Every source of content that an agent ingests is a potential injection vector. The OWASP Agentic Top 10 identifies Agent Goal Hijack (ASI01) as the top risk specifically because agents cannot reliably distinguish legitimate instructions from adversarial content embedded in external data.
The framework requirement: build an explicit trust tier for every content source the agent accesses.
Tier 1 (System prompt + verified user messages): highest trust, full tool access
Tier 2 (Internal documents and databases with provenance): medium trust, read operations only, no direct tool invocation
Tier 3 (External web content, emails, third-party APIs, scraped data): lowest trust, no access to sensitive tools or credentials, output inspection before delivery
In Axiom Engine, this manifests as the Prosecutor Agent layer: every claim generated from Tier 3 content must be traced back to a verified source coordinate before it can pass downstream. Nothing from untrusted sources propagates to consequential actions without audit. This is not a post-processing filter. It is an architectural constraint built into the pipeline.
Domain 3: Tool Use and Action Controls
Unsafe Tool Execution (ASI02) is the second-highest OWASP agentic risk for a reason. Agents call tools with fabricated parameters, invoke APIs with unverified identifiers, and execute irreversible actions before any human has a chance to review them. The Vercel hallucination incident is the canonical production example.
The framework requirement: every tool call that can produce an irreversible, high-consequence, or externally visible action must pass through three gates before execution:
Verification gate:
the parameter driving the action was retrieved from an authoritative source, not assumed or generated. No deployment without a confirmed repository ID. No financial transaction without a confirmed account number. No data deletion without a confirmed record identifier.
Least-privilege gate:
the agent’s current permission set covers this specific action. If it does not, the action fails with an escalation signal rather than attempting to acquire additional permissions.
Human approval gate:
for irreversible actions — deployments, database mutations, financial transactions, credential changes — a human checkpoint is mandatory. LangGraph’s interrupt() function provides the mechanism. This is not optional for consequential operations.
Domain 4: Memory and State Integrity
Memory Tampering (ASI05) is the sleeper risk in agentic security. Unlike prompt injection, which ends when the session ends, memory poisoning persists. A false instruction planted in an agent’s long-term storage persists across sessions, gets recalled as a legitimate directive, and is defended as correct when questioned. Lakera AI’s November 2025 research demonstrated this in production systems.
The framework requirement:
Never store raw user input in long-term memory. Store structured, vetted summaries only.
Apply memory isolation per user, per session, and per task — no cross-contamination of context between tenants or roles
Log all memory mutations and require human approval for any goal-altering changes
Implement a memory lifecycle with explicit expiry: IBM’s security framework recommends a 20,000-token hard cap to force predictable context boundaries and prevent unintended credential accumulation across sessions
Periodically purge and re-baseline long-term memory to remove drift or contamination
Domain 5: Supply Chain and Dependency Integrity
The TeamPCP campaign across Trivy, KICS, and LiteLLM in March 2026 is the definitive 2026 case study for why supply chain integrity belongs in every AI agent security framework. LiteLLM’s backdoored versions passed all standard pip integrity checks because they were published using legitimate credentials. The malicious content was not detectable by hash verification alone.
The framework requirement:
Treat AI plugins, skills, MCP servers, and agent framework dependencies as critical infrastructure — not developer convenience tools
Pin every dependency to an exact version with a verified hash. Implement pip install --require-hashes in all production environments
Disable automatic updates for AI skills and plugins in production. Updates must go through the same review process as new installations
Audit for .pth file installation: any package that installs .pth files with execution patterns (subprocess, base64, exec) should trigger an immediate security review
Subscribe to PyPA security advisories and the CVE feeds for every AI framework in your dependency tree
The LiteLLM compromise was discovered by a researcher whose Cursor IDE pulled it in as a transitive dependency of an MCP plugin they never explicitly installed. Your supply chain is wider than the packages you intentionally install.
Domain 6: Observability and Incident Response
You cannot govern what you cannot see. Only 21% of executives currently have complete visibility into agent permissions and data access patterns. Only 24.4% of organisations know which of their agents are communicating with each other. The observability gap is the enforcement gap.
The framework requirement:
Full trace-level logging: every tool call with inputs, outputs, and timestamps. Every external content ingestion point. Every inter-agent message. Every memory mutation.
Anomaly detection on tool-call sequences: not just individual calls, but patterns. A deployment with zero prior lookup calls is detectable. 88 bot comments in a 102-second window is detectable. These patterns are invisible without sequence-level observability.
Agent inventory: a continuously updated catalogue of every agent in the environment — authorized or not. Shadow AI cannot be governed without visibility.
Kill switches with operational priority: Kiteworks’ 2026 survey found most organisations can monitor what agents are doing but cannot stop them when something goes wrong. The governance-containment gap. Your incident response plan must include the ability to terminate agent actions in real time, not just log them.
Blast-radius testing: before any new agent deployment or policy change, run it through a digital twin environment. OWASP Agentic Top 10 explicitly recommends gating policy expansions on blast-radius caps verified in isolated environments before production promotion.
The Four-Phase Deployment Maturity Model
The Cloud Security Alliance’s Agentic Trust Framework (ATF) proposes a maturity model that maps directly to how organisations should sequence agent autonomy against security control maturity. Applied to the six-domain framework above, it gives you a concrete deployment sequence:
Phase 1: Intern Agent (Read-Only Mode)
Agents at this level can access data, perform analysis, and generate insights. They cannot take any action that modifies external systems. All six framework domains are implemented in read-only enforcement mode. Minimum time at this phase: two weeks before promotion eligibility.
Real-world equivalent: an agent that summarises documents, answers questions from a knowledge base, and generates draft outputs for human review. No tool calls with write access. No external API mutations. No messaging platform integrations.
Phase 2: Junior Agent (Supervised Actions)
Agents at this level can recommend specific actions with supporting reasoning, but require explicit human approval before any action is executed. Domain 3 (Tool Use and Action Controls) is now active: every tool call passes through the verification, least-privilege, and human approval gates. Supply chain integrity (Domain 5) is fully enforced.
Real-world equivalent: an agent that proposes a deployment, presents the verified repository ID and diff for human review, and executes only after explicit approval. This is what should have governed the Vercel incident.
Phase 3: Senior Agent (Selective Autonomy)
Agents at this level can execute pre-approved action classes without human intervention, but escalate to human review for novel or high-consequence operations. All six domains are fully active. Anomaly detection (Domain 6) is enforcing real-time alerts. Memory lifecycle management (Domain 4) is actively expiring and re-baselining context.
Real-world equivalent: an agent that autonomously handles routine deployments within a defined scope, halts and escalates when it encounters a parameter it cannot verify, and automatically pages a human for any action outside its pre-approved action class.
Phase 4: Principal Agent (Full Autonomy with Governance)
Agents at this level operate with broad autonomy within explicitly bounded operational limits. This phase requires clean operational history at Phase 3, a passed security audit, measurable positive impact, and explicit sign-off from authorized stakeholders. No agent reaches this phase without evidence from the lower phases.
The critical point: most production agents should not be at Phase 4. The instinct is to maximise autonomy. The discipline is to match autonomy level to the maturity of your controls and the evidence from your operational history.
OWASP’s principle of least agency is the governing constraint of this maturity model: only grant agents the minimum autonomy required to perform safe, bounded tasks. Autonomy without sufficient control maturity is not a capability. It is a liability.
The Pre-Deployment Checklist: 20 Questions Before Any Agent Goes Live
Before any agent moves to production — regardless of how simple it seems — answer all 20 of these questions. If any answer is ‘no’ or ‘not yet’, the agent is not ready for production.
Domain 1: Identity and Access
Does this agent have a unique identity distinct from human users and shared service accounts?
Are credentials scoped to the minimum permissions required for the agent’s specific tasks?
Do credentials expire after task completion, or are they long-lived?
Is this agent included in your access review process?
Domain 2: Input Trust Boundaries
Have you mapped every external content source this agent will ingest?
Is there an explicit trust tier applied to each content source?
Does the agent have a mechanism to flag or reject anomalous instructions embedded in Tier 3 content?
Domain 3: Tool Use and Action Controls
Does every irreversible action require parameter verification against an authoritative source?
Is there a human approval checkpoint for deployments, database mutations, and financial transactions?
Does the agent fail safely (escalate, not proceed) when it cannot verify an action parameter?
Domain 4: Memory and State Integrity
Is there a token cap on long-term memory context?
Are memory mutations logged and auditable?
Is memory isolated per user, session, and task?
Domain 5: Supply Chain and Dependency Integrity
Are all AI dependencies pinned to exact versions with verified hashes?
Are AI plugins and skills from verified sources with documented provenance?
Are automatic updates disabled in the production environment?
Domain 6: Observability and Incident Response
Is full trace-level logging in place for all tool calls and external content ingestion?
Is there a continuously updated agent inventory covering this deployment?
Does your incident response plan include the ability to terminate this agent’s actions in real time?
Has this agent been tested in a digital twin environment with defined blast-radius caps?
The Framework Is the Deployment Gate
The instinct under time pressure is to ship the agent and add security later. Q1 2026 has demonstrated what ‘later’ costs in practice: production incidents, credential rotations across thousands of environments, public incident disclosures, and the kind of trust damage that takes quarters to repair.
The six-domain framework above is not a compliance exercise. It is the minimum viable governance structure for an autonomous system that can take real actions in the world on your behalf. It does not require exotic tooling or a dedicated AI security team. It requires disciplined engineering and a willingness to make framework completion a deployment gate, not a post-launch audit item.
Bessemer’s CISO framework guidance puts it well: the framework should follow the strategy, not precede it. Define your organisation’s position on agents — how much autonomy, in which contexts, with which oversight structure — and then build the controls that match that position. But whatever your position, build the controls first.
The teams that got burned in Q1 2026 did not lack the capability to build these controls. They lacked the discipline to build them before deployment. The framework is not the obstacle to shipping agents. It is what makes shipping agents sustainable.
Case studies from this series:
AI Agent Security: The Complete Guide
What Are the 4 Biggest AI Agent Security Risks in 2026?
Claude Hallucinated a GitHub Repo ID and Deployed It to Production